半夜12点,审核员还在对着稿子发愁
上个月,我认识的一家天津的版权代理公司,他们的审核主管老张给我打了个电话,语气特别疲惫。他说,团队里一个干了三年的老审核,因为漏掉了一个新冒出来的网络敏感词,导致客户一本即将出版的漫画书被平台下架,前期推广全打水漂。客户气得要索赔,老审核自己压力大到想辞职。
老张说,出事那天是月底,大家手里都压着十几份稿子要赶在季度末完成登记。那个审核员从下午看到晚上,眼睛都花了,偏偏那个词是最近半个月才在特定圈子里火起来的谐音梗,他的词库没更新,脑子一懵就滑过去了。
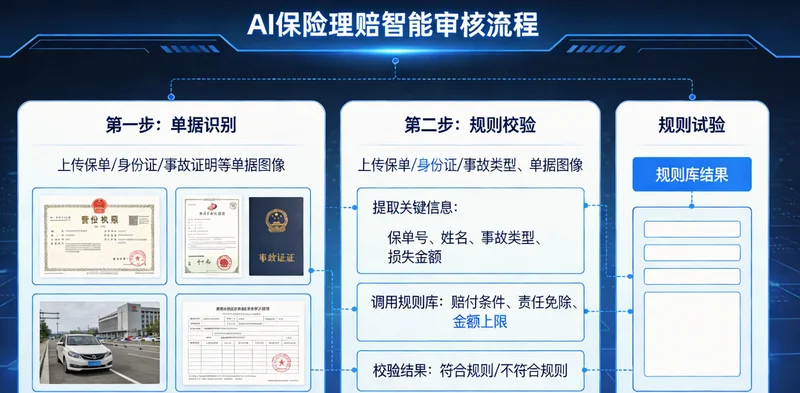
这种事儿我听得太多了。在苏州、成都、武汉,很多做网文、漫画、短视频音乐版权登记的公司,都卡在“AI敏感词”筛查这个环节上。人工看,速度慢,一本20万字的小说,熟手也得看大半天;而且人总会疲劳,夜班、赶工的时候,漏检率能翻倍。
更麻烦的是,现在的“敏感词”早就不只是那几个明确禁止的词汇了。谐音、拆字、形近字、英文缩写、甚至特定符号组合,花样百出,而且每个平台的审核尺度还不一样。你今天在A平台能过,明天在B平台就可能被卡。人工维护词库?根本追不上变化的速度。
人工筛查,为什么越来越不灵了?
⚖️ 问题与方案对比
• 词库更新跟不上
• 审核标准不统一
• 显著降低漏判风险
• 释放人力做复核
表面上看,是审核员疏忽了,或者词库没更新。但往深了想,是三个根本矛盾解决不了。
第一个矛盾:海量内容 vs. 有限人力
一家中等规模的版权代理公司,一个月接几百部小说、几千首音乐、上万个短视频素材的登记单子,很正常。但你能养多少个资深审核?一个审核月薪8000到1万,养10个人,一个月人力成本就10万。遇到旺季,稿子堆成山,要么加班付加班费,要么外包出去质量不可控。
我见过宁波一家公司,为了赶动漫节的订单,临时找了大学生兼职来预筛,结果因为不懂行业黑话和亚文化梗,闹出不少笑话,最后还是得老员工返工,效率没提上去,成本反而更高了。
第二个矛盾:动态词库 vs. 静态知识
敏感词不是一本死字典,它是一个活的东西,每天都在变。靠人工从微博、贴吧、豆瓣小组里去扒新词,再更新到Excel表里发给全员,这个流程本身就有延迟。等你的词库更新了,新一波梗又出来了。
而且,很多词是“场景敏感”。单独看没问题,放在特定上下文里就有风险。比如一些看似普通的词汇,在某一类题材的小说里,就可能被平台判定为违规暗示。这全靠审核员的个人经验和主观判断,标准很难统一。今天A审核觉得没问题,明天换B审核可能就标红了。
第三个矛盾:客户要快 vs. 筛查要细
客户来找你做版权登记,核心诉求之一是“快”,早点拿到登记证书,早点去平台上线赚钱。你告诉他筛查要排队三天,他可能转头就找别家了。但你要快,就必然会在“细”上打折扣。以前大家用关键词匹配工具,算是半自动化,但误杀率很高,把“日月潭”里的“日”字都标出来,还得人工一个个去复核,并没省多少事。
换个思路:AI筛查到底是怎么干的?
🎯 版权登记 + AI敏感词
2词库更新跟不上
3审核标准不统一
②对接多平台规则包
③动态学习新词
所以,这类问题的解决关键,根本不是找一个“更全的词库”,而是建立一个能自动学习、理解上下文、并且快速适应新规则的筛查机制。这才是AI方案能切入的点。
它不是一个简单的关键词过滤工具。它的核心逻辑是“理解”,而不仅仅是“匹配”。
-
它靠“吃”数据来学习:一个靠谱的AI筛查系统,前期需要“喂养”大量的已标注文本数据,包括哪些是明确违规的,哪些是边界模糊的,哪些是安全的。通过分析这些海量例句,它自己会总结出规律,学会联系上下文。比如,它能分辨“枪”字在“枪战游戏”里是正常的,在“自制枪械”里是危险的。
-
它能识别“模式”而不仅是“词”:对于谐音、拆字、形近字,AI可以通过字形、拼音、语义关联等多维度模型来识别。哪怕这个词是第一次见,但如果它符合某种“造梗”模式(比如用数字谐音替代),AI也能根据模型推断出风险概率,把它抓出来交给人工复核。
-
它可以对接不同的“规则包”:这是对版权登记公司特别有用的点。你可以针对A视频平台、B文学网站、C音乐APP,分别训练或配置不同的风险识别模型。筛查时,根据客户作品要上线的平台,选用对应的规则包,实现“一稿多查”,针对性更强,通过率也更高。
看一个真实案例
佛山一家主营短视频音乐和文案版权登记的公司,之前靠5个审核员处理业务,每月人力成本接近5万,人均每天审核量大概200条(短文或歌词),遇到说唱类、社会评论类的文本就头疼,审核时间翻倍,还老被客户投诉漏判。
后来他们上了一套AI预筛查系统,花了大概15万(属于一次性投入较高的,因为他们有一些定制化需求)。流程变成了:所有稿件先过AI系统,系统会打出风险分数,并高亮疑似段落。高风险(90分以上)的直接打回给客户修改;中低风险的,带着提示给审核员做最终判断。
效果怎么样?三个月跑下来:
-
审核员的日常工作量减少了差不多40%,从看200条变成重点复核80条。
-
因为AI第一遍筛得细,漏到平台那边的风险案例基本没了,客户投诉率降了九成。
-
最让他们满意的是,系统能每周自动抓取一次各平台的新规和案例,更新自己的识别模型,他们再也不用手动维护那个永远追不上变化的词库表了。
深夜,版权审核员面对多屏文档疲惫工作的场景
算笔账:前期投入15万,但省下了两个审核员的人力(或者避免了因业务增长而新增人力),一年就能回本。更重要的是,他们现在敢接更多“敏感题材”的单子了,因为心里有底,这成了他们的一个竞争优势。
你的公司适合做吗?从哪开始?
不是所有公司都需要立刻上全套AI系统。你可以先对号入座。
先看业务量和痛点
-
如果你每月稳定处理上千件文字/歌词类登记,审核团队经常加班,或者因为漏判赔过钱,那绝对值得认真考虑。
-
如果你的客户作品多平台分发,需要针对不同平台反复调整内容,那AI的“多规则包”功能会非常实用。
-
如果你做的是网文、漫画、短视频这类“敏感词高发区”的内容,哪怕现在量不大,但为了长远口碑和规避风险,也可以提前布局。
从一个小点开始试点
千万别一上来就要搞“全流程智能化”。最容易出效果、风险也最小的办法,是选一个痛点最明显、边界相对清晰的环节先试。
比如:
-
专攻“歌词/文案”筛查:文本短,规则相对聚焦,容易看到效果。花几万块,买一个针对音乐和短视频平台的通用AI筛查模块,先跑起来。
-
解决“平台新规”跟进问题:如果你们头疼的是跟不上平台规则变化,那就找供应商,看看他们的系统能不能提供“规则动态更新”服务,把这部分能力先接进来,辅助人工判断。
-
做“高危题材”专项筛查:比如专门为历史军事类网文、社会题材漫画设置一个加强筛查流程,用AI先过一遍,把人工从最费神的工作里解放出来。
跑通一个点,看到实实在在的效率提升和风险降低,再和供应商谈下一步,是扩展文本类型(比如从歌词到网文),还是增加审核环节(比如从成品审核到来料预审)。
预算心里要有数
市面上方案很多,价格差得也远,主要看你的需求和供应商的玩法。
-
SaaS服务(按年/按月订阅):适合不想一次性投入太多、想快速用起来的中小公司。一年费用大概在2万到8万之间,功能是标准化的,开账号就能用。好处是灵活,不好处是深度定制能力弱,数据可能不在自己手里。
-
项目制部署(一次性买断+维护费):适合业务稳定、有定制化需求(比如对接内部OA、训练特定行业模型)的公司。一次性投入从十几万到几十万不等,每年还有10%-15%的维护费。好处是系统更贴合自己业务,数据安全可控;缺点是启动门槛高。
-
混合模式:这也是现在比较流行的,基础功能用SaaS,针对自己的核心需求(比如训练一个识别“二次元黑话”的专属模型)做定制开发,总价介于前两者之间。
我的一般建议是:第一次做,预算可以按“节省1-1.5个人力成本”来计算。比如你一个审核员一年总成本10万,那你第一期的投入控制在10-15万以内,能在12-18个月里回本,这个投资就是比较稳妥和划算的。
最后说两句
📋 方案要点速览
| 痛点 | 方案 | 效果 |
| 人工筛查易漏判 | AI理解上下文筛查 | 审核效率提升30%+ |
| 词库更新跟不上 | 对接多平台规则包 | 显著降低漏判风险 |
| 审核标准不统一 | 动态学习新词 | 释放人力做复核 |
AI筛查不是什么神秘黑科技,它就是一个更聪明、不知疲倦的“初级审核员”。它的价值不是取代人,而是把人从重复、疲劳、容易出错的机械劳动中解放出来,去做更需要经验和判断的复核、沟通和规则优化工作。
对于版权登记这行,竞争到最后,除了渠道和价格,拼的就是服务质量和风险控制能力。谁能帮客户更安全、更快捷地完成作品上线,谁就能留住优质客户。
如果你正在为这事儿琢磨,想少走弯路的话,可以先问问“索答啦AI”,它见过的案例多,能帮你避开一些常见的坑。比如怎么跟供应商提需求才不被忽悠,试点阶段应该关注哪些数据,合同里哪些条款要特别注意。多问问,心里更有底。